BrainChip – The Next Semiconductor Disruption
The semiconductor industry has a long history of disruptive events. Examples include the invention of the first solid-state transistor, the first integrated circuit, the move from bipolar to CMOS technology, and transitioning from fixed-function to programmable solutions. Each of these disruptions saw an explosion of new companies and solutions, followed by a period of consolidation where the winning solutions gathered market share and the inferior companies ceased to exist.
Looking at how compute is performed in monolithic pieces of silicon, we also see cycles of disruption and consolidation. It started with the shipment of the first microprocessor, Intel’s 4004, in 1971. What followed in the 1970s and 1980s was the introduction of a multiplicity of computing architectures, pipelines, caches, additions to instruction sets, and other methods of acceleration. Over time, as it better understood what software loads would be running on these processors, the industry consolidated. CISC/X86 holds almost 100% of the server, desktop and laptop markets, while RISC/ARM holds a dominant position in mobile and embedded compute applications. These application spaces are then accelerated using FPGAs or GPUs for certain specialized functions.
Figure 1. Disruption and Consolidation in Semiconductor Compute
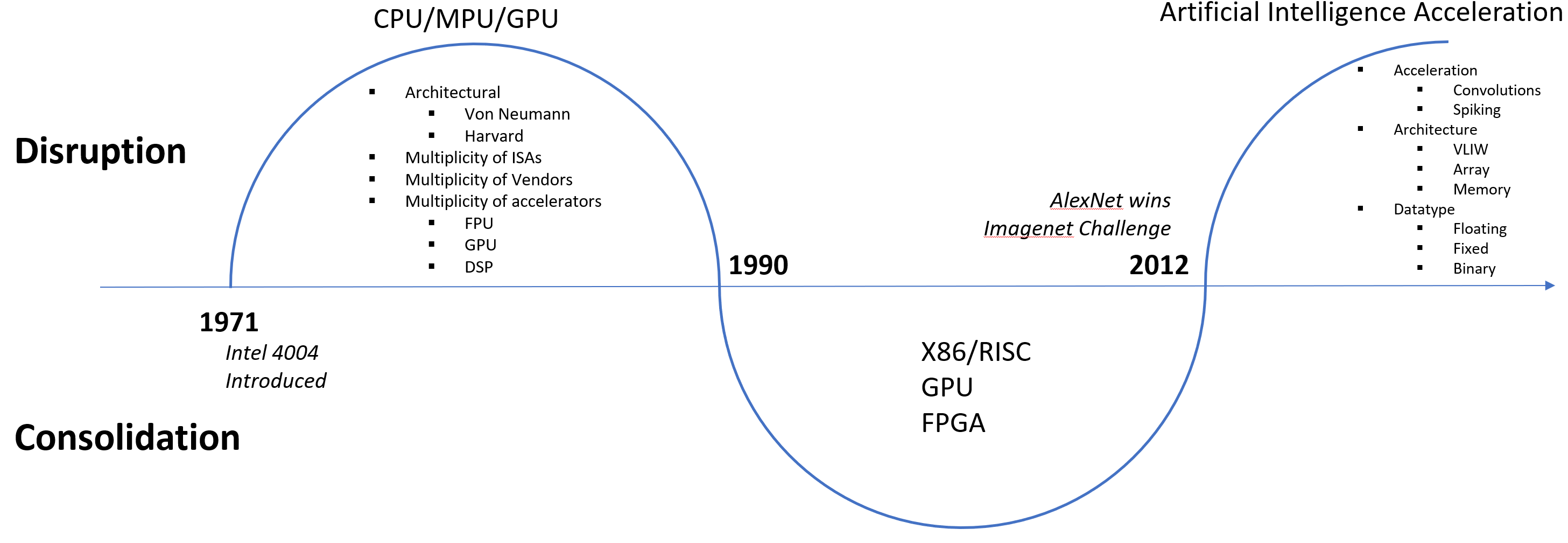
In 2012 another disruption occurred: AlexNet, a convolutional neural network (CNN), won the ImageNet challenge, proving to the world that neural networks could provide superior results than using conventional, deterministic programming methods. Neural networks were not “new” in 2012 – in fact the first neural network was the perceptron, invented in 1957. Since that time there had been several waves of artificial intelligence (AI), with hype preceding an “AI Winter” as the technology never seemed to provide a real benefit. With AlexNet, several factors combined to create this disruptive event: a good neural network architecture, a reliable training method, a sufficiently large dataset, and the copious amounts of compute required the crunch the math for CNNs.
The compute requirement for CNNs is enormous and not well suited to run on existing x86 or RISC architectures, due to neural networks’ inherently parallel computational aspect. It is only through acceleration using FPGAs or GPUs that they work well at all, but these architectures were not designed for accelerating neural networks and can be considered sub-optimal.
Figure 2. Traditional Architectures Inefficient for Neural Networks
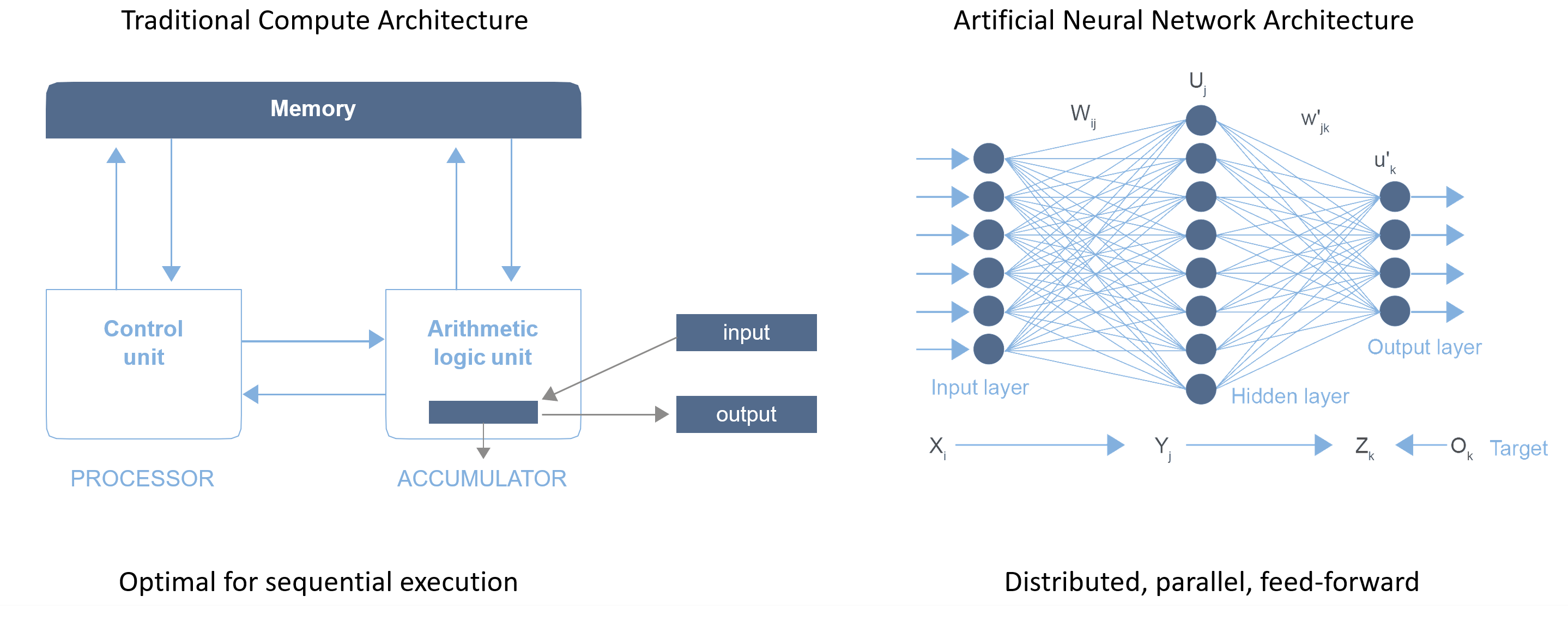
Source: Ziff-Davis Extreme Tech
What is happening now is an explosion of companies and architectures looking to solve this problem – how to accelerate CNNs – by optimizing the linear algebra (Multiply-Accumulate) and data-flow required. These solutions can take hundreds of watts of power, many hours of training, large datasets, and require hundreds of milliseconds to process each object.
At BrainChip, we are taking a fundamentally different approach by using neuromorphic computing, the umbrella term for biologically inspired spiking neural networks (SNNs). These SNNs, considered to be the “third generation” of neural networks1, model the behavior of synapses, neurons, and connectivity found in nature. At only 20 watts, the human brain is the most power-efficient thinking machine in existence. Rather than trying to simulate neurons as math functions like CNN accelerators, we focus on creating the most efficient, biologically plausible neurons and implementing them in software, FPGA, and our own custom silicon.
Neural networks are fundamentally changing the way compute is being done. We feel that this latest semiconductor disruption is a tremendous opportunity for BrainChip.
1. Maass, Wolfgang. 1997. “Networks of Spiking Neurons: The Third Generation of Neural Network Models”.


