Virtual Conference turns AI Chips into Reality
via EET India
The virtual Linley Spring Processor Conference was heavily influenced by AI chips and IP from both established companies and startups, much like last year’s Fall Processor Conference. This is a trend that shows no sign of abating any time soon. Some of the presenting companies were repeats from the fall, but many made significant product announcements. And, like the fall conference, not all the news was AI related — SiFive, for example, had two presentations touting the new RISC-V vector instruction set extensions.
The Linley Spring Processor Conference could not be held in person due to a shelter-in-place order by the county of Santa Clara and the state of California. The COVID-19 pandemic has certainly slowed the conference business and some conferences were simply canceled. In just three weeks’ time, the Linley Group pivoted to a virtual conference using the Zoom video conference service. Despite the changes, and the loss of in-person networking, over 1,100 people registered for the digital conference and the sponsor support was strong.
We can finally grok what Groq is doing
One of the outstanding presentations came from Groq’s chief architect, Dennis Abts, the secretive startup that was formed from some of the design team that developed Google’s original inference Tensor Processing Unit (TPU). The company’s design goal was to produce peak inference results in batch size 1 for responsive and predictable (deterministic) behavior. The chip supports both integer and floating-point data processing for inference and training. While the company had been particularly vague about its chip architecture, they finally explained how it re-architected the machine learning processor.
Rather than cluster processing elements, storage, and communications into little processing elements connected by meshes — as most companies have done — the company de-composed those processing elements into slices of like elements. Data flows from slice to slice in a statically managed data flow with instructions flowing up the slices and times to meet the right data at the right time.

The key to making the Groq design work is that the compiler needs to be able to manage the data in time and location on the Groq chip. With this design, the company claims it will make the chip extremely efficient in compute per area. This allows data-level parallelism and up to 144-way instructions-level parallelism. With no on-chip instruction control stores per processing element, more transistors can be allocated to compute and not control. The chip and array of chips is treated by the compiler as one giant chip, which can yield exceptional deterministic performance.
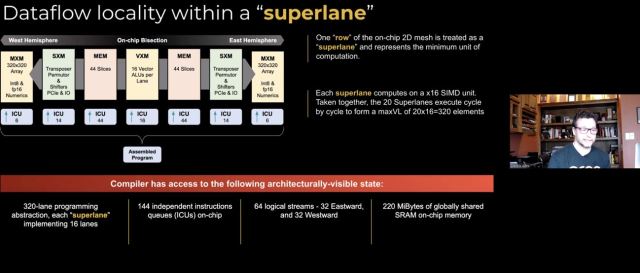
The company’s first chip can support peak computation performance of 750 Tera-operation per second (TOPS) at 900 MHz. This chip is being manufactured in 14 nm and has a die area of 723 mm2 — a very large die. The design goal is to get the chip up to 1 GHz. While we don’t have validated third-party benchmark data, the company claims a 21,700 ResNet-50 images/second score, which would put it ahead of industry leader Nvidia. The Groq chip can also be connected together into larger arrays for greater scaling.
The real challenge now for Groq will be the development of general-purpose compiler software. While benchmarks are easy to tune, the real proof of the architecture is getting random customer workloads run through the compiler and producing efficient results. Still, this is a very interesting approach.
Tenstorrent runs through it
Another data center AI chip comes from Canadian startup Tenstorrent. The company is also targeting inference and training, but uses a more traditional general-purpose architecture. Like Groq and GraphCore, Tenstorrent wants to put the burden on compiler software to manage the complexity.
The chip is composed of a 2D-torus connects series of Tensix cores. Inside each Tensix core are five RISC controllers that control the processing flow. Each compute engine can execute up to 3 TOPS. Data packets arrive at the Tensix, are decompressed, operated on, and then repacketized and shipped to the next unit.
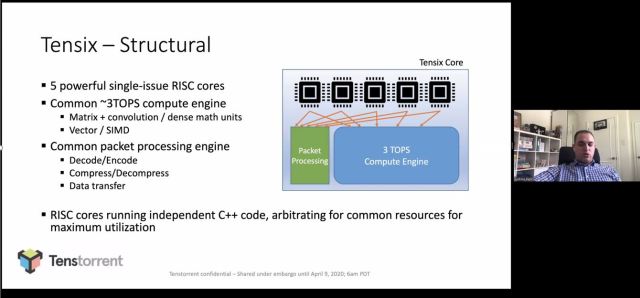
With the more general-purpose and flexible architecture, the Tenstorrent chip is capable of allocating a different amount of Tensix cores for each layer of the neural net. In the picture below, the architecture is optimized for batch 1. The torus network on chip (NoC) can be reconfigured for deeper batches and multitenancy is also supported.
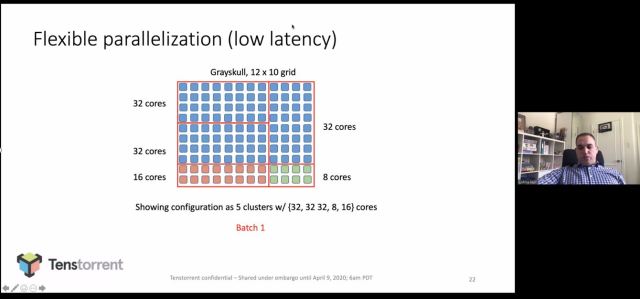
The first major Tenstorrent chip (code named Grayskull) was built in Global Foundries’ 12 nm process and is capable of 368 TOPS, and at 65 Ws, it is suitable for inference servers. A new chip will be taped out in June that will scale to training workloads. Both Groq and Tenstorrent devoted only one slide to software — which is critical to the success of each company — but it is a hardware conference, so the oversight is understandable.
While Groq and Tenstorrent are shipping early evaluation samples, the other data center AI startup at the conference, Cerebras, is shipping full systems. The company has a lead on the new companies, but the Cerebras system is like no other. The company didn’t reveal any significant new information of its wafer-scale processor, but it was interesting to compare design approaches to processing elements. The key design elements for Cerebras were to save energy processing sparse functions by suppressing zero operands and to bring as much memory to the processing elements across the chip as possible. And then just scale everything up to a full wafer size (46,225 mm2) with 1.2 trillion transistors and 18 GB of on-chip memory.
Go small or go home
The other AI presentations mostly focused on extremely low power or network edge applications.
The ultralow power AI chip vendors included GrAI Matters Labs and Brainchip. Both chip companies have taken unique approaches to ultralow power inference based on the spiking neural net (SNN) approach and both companies presented back in the fall. Brainchip’s first chip, the AKD1000 is expected to sample in the second half of this year and the company is focused on the video processing market. GrAI Matter Labs’ chip, called GrAI One, is sampling along with its development software development kit.
The world’s most prevalent processor IP company, Arm has a new set of IP for running machine learning (ML) workloads on microcontrollers. Much of the real volume of ML workloads in IoT applications will run on microcontrollers. Arm released a new set of SIMD instructions for Cortex-M processors called Helium last year and released a new IP core, the Cortex-M55, that uses the new instructions, earlier this year.
To give the Cortex-M55 an additional boost in ML performance, Arm also has the Ethos-U55 microNPU accelerator. The U55 runs in parallel with the M55 and manages data through a shared scratchpad SRAM. With the addition of the U55, the Arm Cortex-M55 can handle workloads such as gesture recognition, biometric parameters, and speech recognition without needing a Cortex-A processor.
FlexLogix continues its pivot from general-purpose FPGA IP provider, to DSP and machine learning IP and chip supplier. When the company was first founded, machine learning was something you did on CPUs and GPUs, not often with FPGAs. But with continued interest in ML by some of its users and by other FPGA vendors (and probably by the FlexLogix investors), the company built a chip architecture that combined DSP elements with FPGA elements. The company’s mmMAX DSP core makes the chip much more efficient at running FIR filters than just using general FPGA multiply-accumulate functions. For DSP functions, FlexLogix competes directly with Ceva. The mmMAX can run up to 933 Mhz in the new InferX X1 chip. The chip is now in silicon and initial benchmarks show that it has competitive inference per watt compared with Nvidia GPUs and it is optimized for streaming edge inference (GPUs perform better when they batch jobs). General availability will be in the third quarter of this year.
IBM had a keynote presentation on its research work to reduce inference power by reducing the number of bits required while maintaining enough accuracy and in-memory compute. The bit diet is showing promise to 4 bits and below but does run out of bits to reduce very quickly. The in-memory compute research uses an analog memory cell to hold neural net weights. Various memory cell types are being evaluated, including phase change memory, but each has challenges in linearity, speed, longevity, and wear tolerance. The research continues, with the goal to continue to scale inference over the next decade.
Performance Still Matters
The more traditional processor vendors Centaur, Marvell, and SiFive presented chips and architectures that focused on performance.
Centaur is a name you probably haven’t heard in a long time. It’s the U.S.-based x86 processor design team for Taiwanese-based VIA Technologies. The Centaur designs were typically known for small die size and low power. But while the company has been in a quiet mode for years, it was working on a chip that is quite extraordinary, even more so when you realize it was developed by an extremely small design team. The company has built a server-class x86 processor and while they were at it, incorporated a large ML co-processing block on the die. The chip includes eight superscalar x86 CPU cores that run at 2.5 Ghz. For the ML accelerator, the company went with a massively wide SIMD approach – 32,768 bits wide (4096 bytes)! Based on its design experience with x86 SIMD, the engineering team achieved good compute density and scalability.
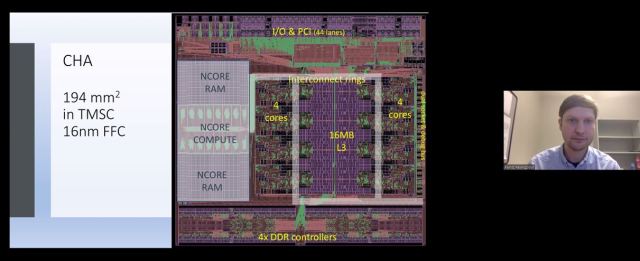
The Centaur chip (called CHA) has put up some impressive preview inference benchmark numbers on the MLPerf website. Much like the other ML chip startups, Centaur will have to show that it can develop more generalized tools to be effective at workloads other than benchmarks. But unlike other startups, a company as small as Centaur can easily be happy on a few niche design wins.
SiFive spent two sessions talking about the new vector extensions to the RISC-V instruction set. It appears now that the Berkley RISC processor was always going to be a vehicle to resurrect the vector processor concepts — which went out of fashion back in the 1980s. The vector instructions offer more flexibility and more consistent programming than SIMD instructions. With SIMD, the compilers need to know the configuration of the SIMD structure in order to schedule execution slots and pack the data into the right bit positions. With a RISC-V vector (RVV) instruction, the number of vector registers may change, but the code does not need to change. The RISC-V defines 32 vector registers, but the length and type are dynamic. Vector registers can be grouped to act as a single vector and the extension can work with mixed-width operations. The extension definitions are working through the RISC-V Foundation and should be finalized this year. We have to see what the impact on size and speed of RISC-V cores that implement RVV.
Marvell’s Octeon Fusion system on chip (SoC) addresses a specific market segment that will be growing with the 5G infrastructure — edge servers for radio access networks (RAN). The Fusion chip has six Octeon Arm cores, 25G SerDes support, baseband DSP processors, 4G/5G accelerator blocks, and a fast interconnect fabric. The Octeon Fusion can also be combined with the company’s Octeon TX2 and ThunderX2 processor to handle the complete open RAN protocol stack from RF to the Core Network.
Mellanox also brought some hardware muscle for the edge data center. The Mellanox I/O Processing Unit (IPU) is designed to work in highly virtualized/containerized data center applications to offload the CPUs of the virtualized storage, networking, and I/O tasks. This frees more CPU core to focus on the application software. The Bluefield-2 CPU either Arm Cortex-A72 cores along with data path controllers and other networking and I/O accelerators. One key accelerator is the Regular eXpression Processor (RXP) that can perform massive parallel searches on text and can apply up to 1 million rules in parallel. This can be an important tool to help sniff out phishing attacks and other nefarious traffic.
Other established IP providers presenting including: ArterisIP, Cadence, Ceva, Rambus, and Synopsys. Each gave updates on their product lines that address machine learning, sensor fusion, and security.


